I had a discussion with an industry peer today, regarding databases. Two conclusions he arrived at, which are right, but also wrong. One, “strings have no business being in a SQL statement”, two, “IDs have no basis being in a mapping table”. From a peer data storage and efficiency perspective, you’re correct, but from a practically perspective, you’re wrong. The statement about IDs being in a mapping table, from a peer database perspective, you’re correct, and from a real-world perspective, you’re wrong.
Strings have no business being in a SQL statement
The point of readability is to provide the ability to deduce, at a glance, as much information as reasonably possible. So lets say we have the following database table structure:
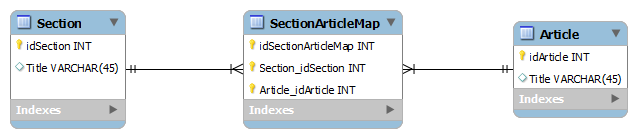
How would you query all the articles of a section? My response is:
SELECT * FROM Section S
JOIN SectionArticleMap SAM ON S.idSection = SAM.Section_idSelection
JOIN Article A ON A.idArticle = SAM.Artcile_idArticle
WHERE Section.Title = ‘Name’
The only response he thinks is acceptable is:
SELECT * FROM SectionArticleMap SAM
WHERE Section_idSection = 1
AND Article_idArticle = 1
He claimed a string has no place being in a SQL statement, he believes there’s only one correct way, and I’m sorry, but he’s wrong. He favors IDs because it’s immutable, and he believes they will remain longer, which is true, but if you look at categories, they’re represented in names, and not IDs. In a sea of SQL statements, I would have to do a lot of grunt work to figure out exactly which section the statement is tied to, if I wanted to re-use, I’d have to figure how which ID to replace it with. The prior allows me to easily figure out the section and re-use the query. The section is called “Name”, and if I need to re-use the statement for another section, I simply change the name.
I’m not saying the prior is THE CORRECT way of doing things, nor am I claiming the later is the INCORRECT way of doing things. What I’m claiming is the strong statement that ‘such things have no business being in a SQL query’ is wrong. The prior is clearly easier to understand than the later. I know at a glance that I’m fetching articles for a section titled “Name”, the later, I’ll have to do some additional queries, and if the titles aren’t maintained in the DB, but in the code, then some code diving, and if the DB structure somehow became unsynced with the code, then some nightmares are due to follow. There are pros and cons for every approach.
IDs have no basis being in a mapping table
I basically add an ID to all tables now and days for cross-platform compatibility. I informed him during my time as a professional developer, I’ve come across scenarios that merited an ID being in a mapping table, in which he countered, that he’s been working professional for 25 years and there is never a case for an ID column in a mapping table, and anything requiring it is just crap code. It appears that during his time he might not have dealt with the need for many different codebases to interface with the same database, or at the very least, not CakePHP. “By convention the ORM also expects each table to have a primary key with the name of id" (http://book.cakephp.org/3.0/en/orm/table-objects.html)
From a database perspective, it’s very easy to say that the ID as a primary key takes up unnecessary space, and is bad practice, but once you factor CakePHP into the picture, then having an ID IS the best practice.
Is CakePHP crap code? I personally don’t think either CakePHP or any software built on-top of it is crap code, there are always room for improvement, but without understanding the rhyme or reason of why things are the way they are, I’m hesitant to claim things as broken.
I’m not a big fan of people with high-technical responsibility being extremely closed minded. Certain solutions aren’t ideal for one-case, but might be ideal for another, which is why in academia, you’re going to hear a lot of “it depends”. People whose lives involve wisdom and learning, often time know that there’s never a clear-cut answer for everything, and everything depends on other factors, why then, is the world so littered with single solution answers?